

Interesting FAQs & lessons from building ETL pipelines related to spark, dataframe, spark sql, configurations.
There are many resources out there to build your own ETL pipeline using spark. These days, web-based platforms are very popular in organisations for working with Spark and one of the most popular one is Databricks. It allows any user to start your own data engineering project at a relatively low-cost and an easy-to-manage automated cluster management.
Get started to build your own ETL pipeline using a simple architecture like below and enhance your understanding of Spark!
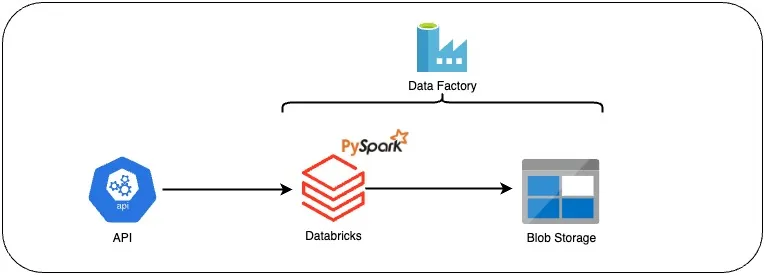
Documenting some interesting lessons along the way of learning Spark…
- 1. How do get the list of all spark configurations?
- 2. With so many
selectmethods using Spark, which is the better one to use? - 3. Why is databricks magic commands so important & useful?
- 4. When to use
.groupByvs.aggmethod? - 5. What is the difference between
createOrReplaceTempViewvscreateOrReplaceGlobalTempViewvspermanent view? - 6. What is the difference between
groupByKeyandreduceByKeyin Spark? - 7. A key feature of Spark is lazy evolution, however why do we need to call cache or persist on a RDD sometimes?**
- 8. When to use
cachevsbroadcastin spark?
1. How do get the list of all spark configurations?
Use spark context directly in the Databricks notebook to call the getAll function.
sc.getConf().getAll()
Another way is via spark instance in the Databricks
spark.sparkContext.getConf().getAll()
How to set a configuration property permanently for all Spark applications run on the same cluster?
It is possible by modifying the spark-defaults.conf file, located in the spark configuration directory.
When you’re working in Databricks, it’s easier. It is via cluster configuration, under Advanced settings, and inside the Spark tab. Refer to Figure 1 sequential numbers in red color to check step by step way to do that.
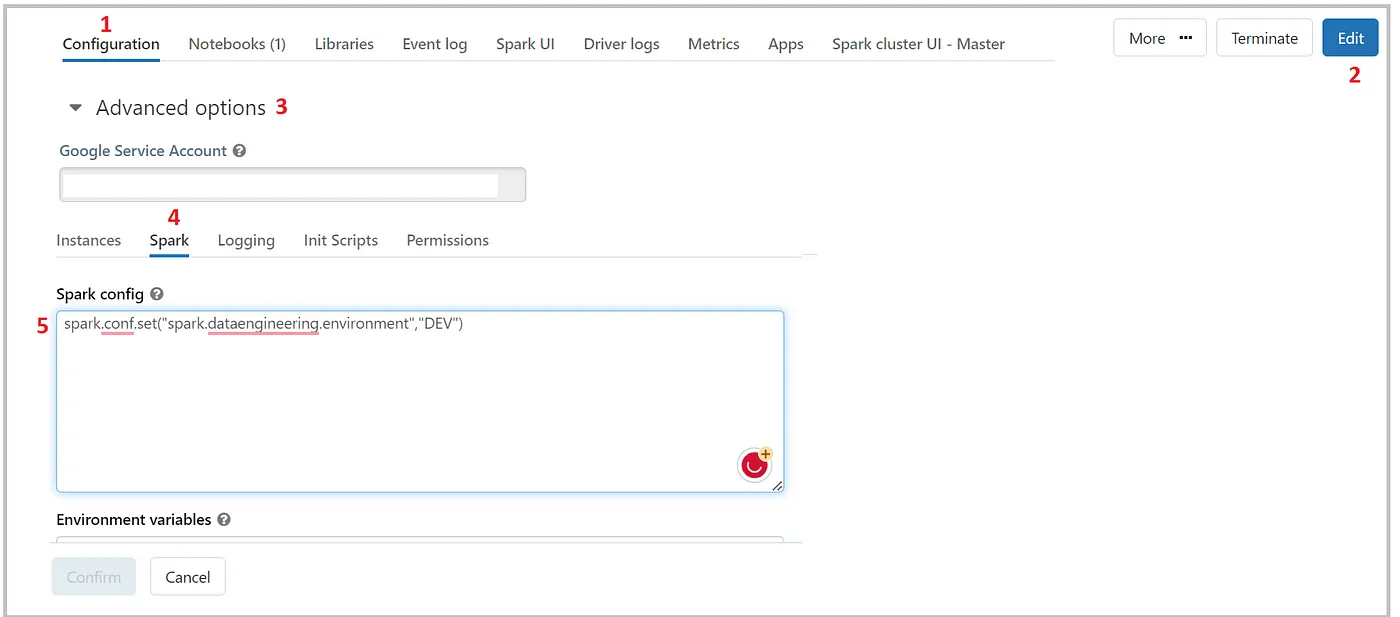
Underneath, the Databricks makes the changes to the same spark-defaults.conf file which is abstracted for Databrick’s users for the sake of simplicity.
Note that, modifying the spark-defaults.conf file will affect all spark applications running on the cluster, thus make sure only the intended properties you can make changes to.
2. With so many select methods using Spark, which is the better one to use?
The first select method below is used in simple scenarios when you do not need to perform other functions. The other 3 select methods allow you to apply column based functions like for eg. alias (changing column name). This give you more flexibility.
#1
df_selected = df.select("id", "name", "location", "country", "lat", "lng", "alt)
#2
df_selected = df.select(df.id, df.name, df.location, df.country, df.lat, df.lng, df.alt)
#3
df_selected = df.select(df["id"], df["name"], df["location"], df["country"], df["lat"], df["lng"], df["alt])
#4
from pyspark.sql.functions import col
df_selected = df.select(col("id").alias("location_id"), col("name"), col("location"), col("country"), col("lat"), col("lng"), col("alt))
3. Why is databricks magic commands so important & useful?
Below list is not an exhaustive list but shows you the list of various useful magic commands you can use in Databricks notebook. Essentially, magic commands allow you to write code in multiple languages using the same notebook!
%run: runs a Python file or a notebook.
%sh: executes shell commands on the cluster nodes.
%fs: allows you to interact with the Databricks file system.
%sql: allows you to run SQL queries.
%scala: switches the notebook context to Scala.
%python: switches the notebook context to Python.
Examples of using magic commands:
- Use magic command %fs to check if the file is written as in dbfs

- Use magic command %run to run your configuration file or common python functions file
4. When to use .groupBy vs .agg method?
You are not able to use .groupBy method if you are intending to perform more than 1 aggregration after the .groupBy method.
# this won't work
demo_df\
.groupBy("driver_name") \
.sum("points") \
.countDistinct("race_name") \
.show()
Instead, consider using the .agg method.
demo_df\
.groupBy("driver_name") \
.agg(sum("points"), countDistinct("race_name") \
.show()
5. What is the difference between createOrReplaceTempView vs createOrReplaceGlobalTempView vs permanent view?
| View | Description | Scenario |
|---|---|---|
createOrReplaceTempView |
A temporary view is only available within a spark session and within the notebook. If you detach the notebook from the cluster and reattach it, this view is not going to be available. | When your scope is only just a notebook → create the temp view and you only need to access it in this notebook |
createOrReplaceGlobalTempView |
A global view compared to a temporary view is available across the whole application and in databricks context, this means the global view is available within all the the notebooks attached to the same cluster. | When you have other notebooks working on the same view |
permanent |
Even if you detach notebook from clsuter or terminate cluster and restart, the permanent view would still exist. | When you have some pipelines accessing to the views directly, eg. monitoring dashboards |
6. What is the difference between groupByKey and reduceByKey in Spark?
Pros and Cons of groupByKey()
The advantage of groupByKey() is that it is a simple operation that does not require any complex logic. However, it can be inefficient for large datasets, because all the values associated with each key are shuffled across the network and stored in memory on the worker nodes. This can lead to high memory usage and slow performance.
Pros and Cons of reduceByKey()
The advantage of reduceByKey() is that it is more efficient than groupByKey() for large datasets, because it reduces the amount of data that needs to be shuffled and stored in memory. However, it requires a reduce function that is associative and commutative, which may not always be the case for all aggregate functions.
In summary, while reduceByKey() is generally more efficient than groupByKey(), there are still situations where groupByKey() may be a better choice due to its simplicity, flexibility, and applicability to non-associative operations. It is important to understand the characteristics of the dataset and the requirements of the operation when choosing between these two methods.
7. A key feature of Spark is lazy evolution, however why do we need to call cache or persist on a RDD sometimes?**
Caching or persistence are optimization techniques for (iterative and interactive) Spark computations. They help saving interim partial results so they can be reused in subsequent stages. These interim results as RDDs are thus kept in memory (default) or more solid storage like disk and/or replicated. RDDs can be cached using cache operation. They can also be persisted using persist operation.
However, just because you can cache a RDD in memory doesn’t mean you should blindly do so. Depending on how many times the dataset is accessed and the amount of work involved in doing so, recomputation can be faster than the price paid by the increased memory pressure.
It should go without saying that if you only read a dataset once there is no point in caching it, it will actually make your job slower. The size of cached datasets can be seen from the Spark Shell!
8. When to use cache vs broadcast in spark?
In Apache Spark, both caching and broadcasting are techniques used to optimize data processing and improve the performance of distributed computations, but they serve different purposes and have distinct use cases.
Caching
Purpose: Caching in Spark is used to persist (store in memory or disk) a portion of a RDD (Resilient Distributed Dataset) or DataFrame so that it can be reused across multiple stages of a Spark application.
- Use Case: Caching is typically used for data that will be accessed multiple times in multiple operations. Examples include intermediate results in iterative algorithms or frequently used reference data.
- Memory Usage: Caching stores data in memory (default) or optionally on disk if there’s not enough memory.
- Storage Level: You can specify different storage levels (e.g., MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY) depending on the trade-off between memory usage and recomputation cost.
- Distribution: Caching is distributed across all nodes in the cluster, ensuring data is available locally on each node.
- Overhead: Caching can consume memory resources, and managing cache usage is important to avoid out-of-memory errors.
Broadcasting
- Purpose: Broadcasting is used to share a read-only variable or data to all worker nodes so that it can be accessed efficiently during task execution.
- Use Case: Broadcasting is appropriate for relatively small data that is used in a read-only fashion, such as lookup tables or reference data that is used by tasks across the cluster.
- Memory Usage: Broadcasting loads the data into memory on each worker node and makes it available for efficient lookups without the need for network transfers.
- Storage Level: Broadcasting doesn’t use Spark’s storage levels; it is purely in-memory.
- Distribution: The data is sent to worker nodes once and reused for multiple tasks, reducing network transfer overhead.
- Overhead: Broadcasting is memory-efficient because the data is loaded only once on each node and doesn’t persist in memory.
In summary, caching is used to store and reuse RDDs/DataFrames across multiple stages of a Spark application, and it can be used for larger datasets. Broadcasting, on the other hand, is suitable for efficiently sharing small, read-only data across worker nodes, reducing data transfer and improving performance.
The choice between caching and broadcasting depends on the size and usage patterns of the data and the specific requirements of your Spark application.
Use cases
- Broadcast - reduce communication costs of data over the network by provide a copy of shared data to each executor.
- Cache - reduce computation costs of data for repeated operations by saving the processed data and its steps (for lookup).